
 DC/OS Documentation
DC/OS DocumentationYou can define health checks for your DC/OS services. Health checks are defined on a per application basis, and are run against that application’s tasks. Health checks perform periodic checks on the containers distributed across a cluster to make sure they are up and responding. If health checks fail for any reason, Mesos will report the task as unhealthy so that status-aware load balancers can stop sending traffic to the container. After a task reaches the maximum number of consecutive failures, Marathon will kill the task and restart it.
Health checks begin immediately when a task is launched. They are locally executed by Mesos on the agent running the corresponding task. Health checks are performed as close to the task as possible, so they are are not affected by networking failures. Health checks are delegated to the agents running the tasks. This allows the number of tasks that are health checked to scale horizontally along with the number of agents in the cluster.
- The default health check leverages Mesos’ knowledge of the task state
TASK_RUNNING => healthy. - Marathon provides a
healthmember of the task resource via the REST API that you can add to your service definition.
A health check is considered passing if both of these conditions are met:
- The HTTP response code is between 200 and 399 inclusive.
- The response is received within the
timeoutSecondsperiod. If a task fails more thanmaxConsecutiveFailureshealth checks consecutively, that task is killed.
You can define health checks in your JSON application definition or in the DC/OS GUI Services tab. You can also define custom commands to be executed for health. These can be defined in your Dockerfile, for example:
{
"protocol": "COMMAND",
"command": { "value": "source ./myHealthCheck.sh" }
}
Health check protocols
DC/OS supports the following health check protocols:
MESOS_HTTPMESOS_HTTPSMESOS_TCPCOMMAND
Health check options
When creating a service, you can configure JSON health checks in the DC/OS GUI or directly as JSON. This table shows the equivalent GUI fields and JSON options.
| GUI | JSON | Default | Description |
|---|---|---|---|
| GRACE PERIOD(S) | gracePeriodSeconds |
15 | Specifies the amount of time (in seconds) to ignore health checks immediately after a task is started; or until the task becomes healthy for the first time. |
| INTERVAL(S) | intervalSeconds |
10 | Specifies the amount of time (in seconds) to wait between health checks. |
| MAX FAILURES | maxConsecutiveFailures |
3 | Specifies the number of consecutive health check failures that can occur before a task is killed. |
| PROTOCOL | protocol |
HTTP | Specifies the protocol of the requests: HTTP, HTTPS, TCP, or Command. |
| SERVICE ENDPOINT | path |
\ | If "protocol": "HTTP", this option specifies the path to the task health status endpoint. For example, “/path/to/health”. |
| N/A | portIndex |
0 | Specifies the port index in the ports array that is used for health requests. A port index allows the app to use any port, such as “[0, 0, 0]” and tasks could be started with port environment variables such as $PORT1. |
| TIMEOUT(S) | timeoutSeconds |
20 | Specifies the amount of time (in seconds) before a health check fails, regardless of the response. |
For example, here is the health check specified as JSON in an application definition.
"healthChecks": [
{
"gracePeriodSeconds": 120,
"intervalSeconds": 30,
"maxConsecutiveFailures": 0,
"path": "/admin/healthcheck",
"portIndex": 0,
"protocol": "MESOS_HTTP",
"timeoutSeconds": 5
} ]
And here is the same health check specified by using the DC/OS UI.
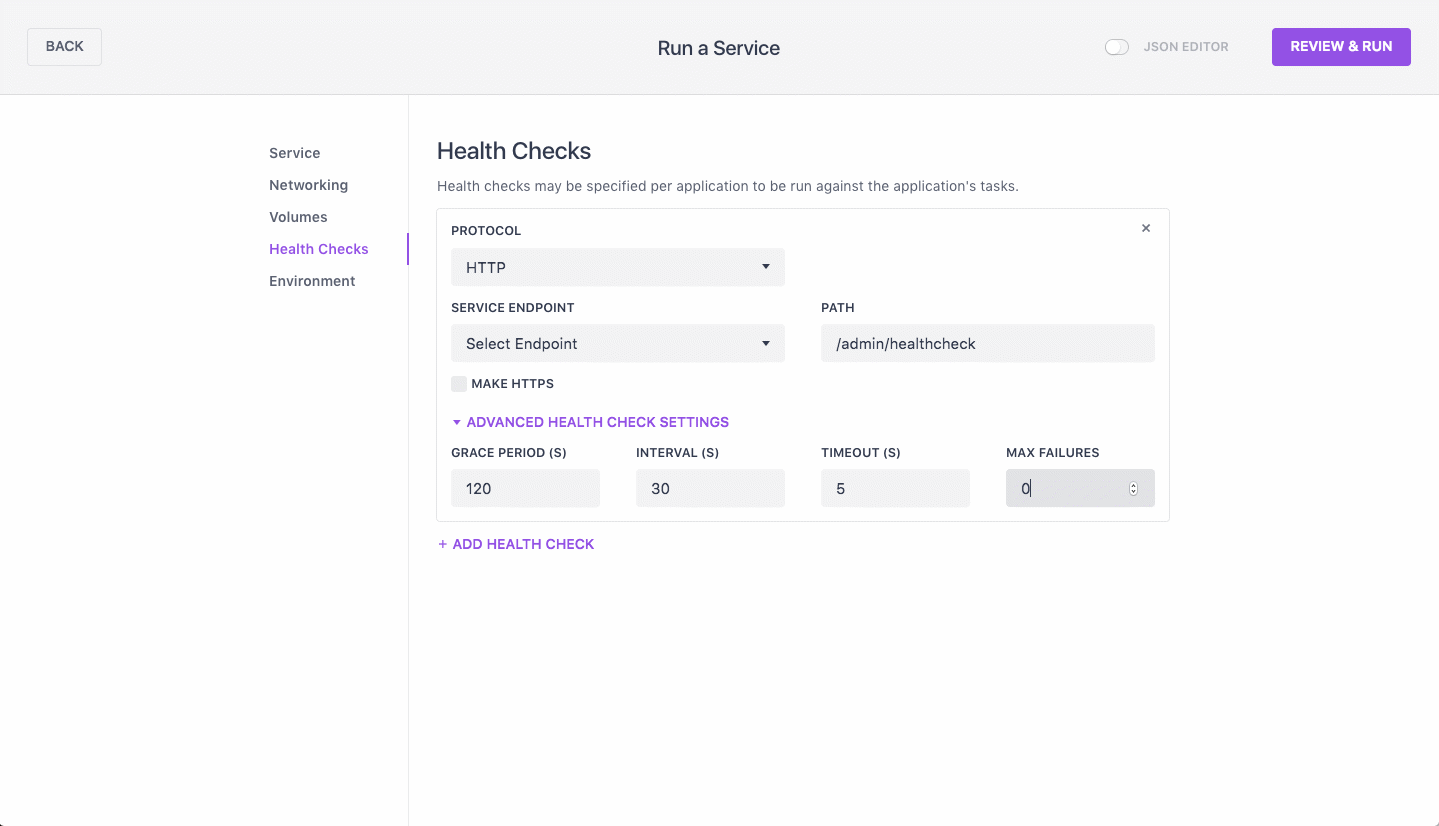
Figure 1. Web interface health check
Command health check performance
When deploying a service which makes use of command health checks, the resources consumed by the health check itself must be considered. If the command executed by the health check requires significant CPU or memory to run, those resources should be added to the resource requirements of the task. In cases where a task only specifies a very small amount of CPU, even a trivial health check will have trouble running reliably, so at least 1.0 CPUs should be specified on any task making use of a command health check.
When tasks specify frequent health checks with an interval of just a few seconds, or when a large number of tasks with command health checks are running on a single machine, the large number of health checks may impact agent performance. Testing has shown that an agent node may have the capacity to run about 10-18 health checks per second, depending on the hardware. In order to estimate the total health check rate your workload may run on an agent, a calculation like the following may be performed:
Health check interval of 30 seconds = 2 health checks per minute
30 tasks running on an agent = 60 health checks per minute, or 1 health check per second
When deploying production workloads which use command health checks, hands-on testing is the most important tool you can use to determine appropriate command health check settings. Before going into production, run tests which execute a realistic number of your services with command health checks on a single agent node, and apply a realistic real-world load to those services in order to determine whether or not the health checks can reliably succeed given the resource allocations you have specified for the tasks.
More information
Check out this blog post for more information about health checks.